多媒体智能体
- 多媒体内容(音频或视频)可通过AI技术进行理解并讲解,并与其他智能体(如文档智能体)互动,支持AI测试功能。
- 一键制作字幕和翻译,再也不用担心听不懂外语资料。
- 长篇文字不想阅读?一键将文本、图片、电子书转换成播客。
- 手机上的视频无法下载?通过听录功能实现上述功能。
- 集成多种图片生成模型,支持AI绘图。
⚠想学川普爷爷的激情演讲?但是和我一样只听得懂MAGA……😵💫,用多媒体智能体就好
多媒体智能学习
多媒体内容(音频或视频)可通过AI技术进行理解并讲解,并与其他智能体(如文档智能体)互动,支持AI测试功能。
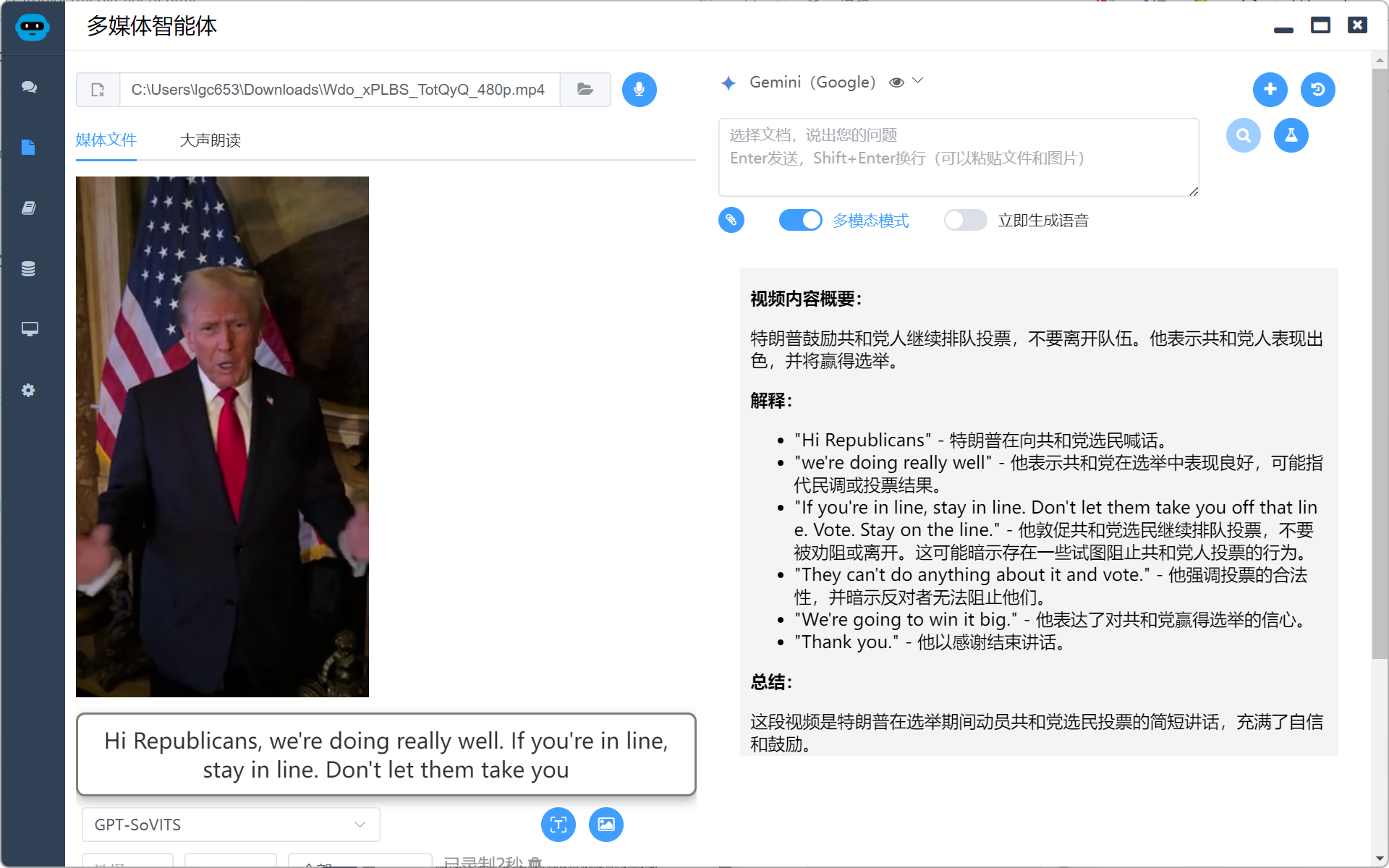
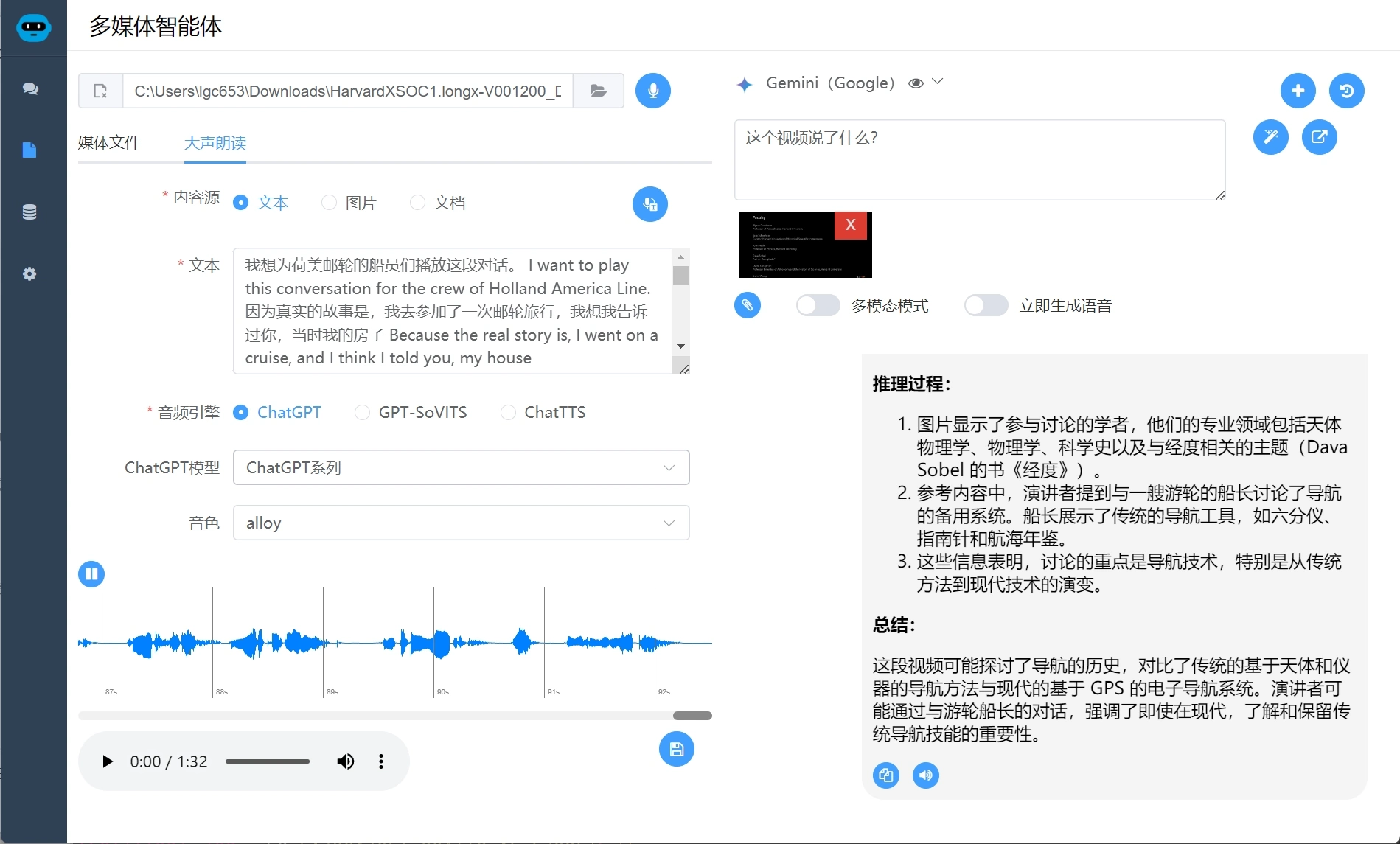
多模态支持,支持识别视频内容并讲解,目前多模态直接解析视频还比较贵,我这里采用的是截取关键图片+语音上下文的方式,可以非常廉价的实现视频的理解,效果也非常不错。
需要点击“多模态模式”选项
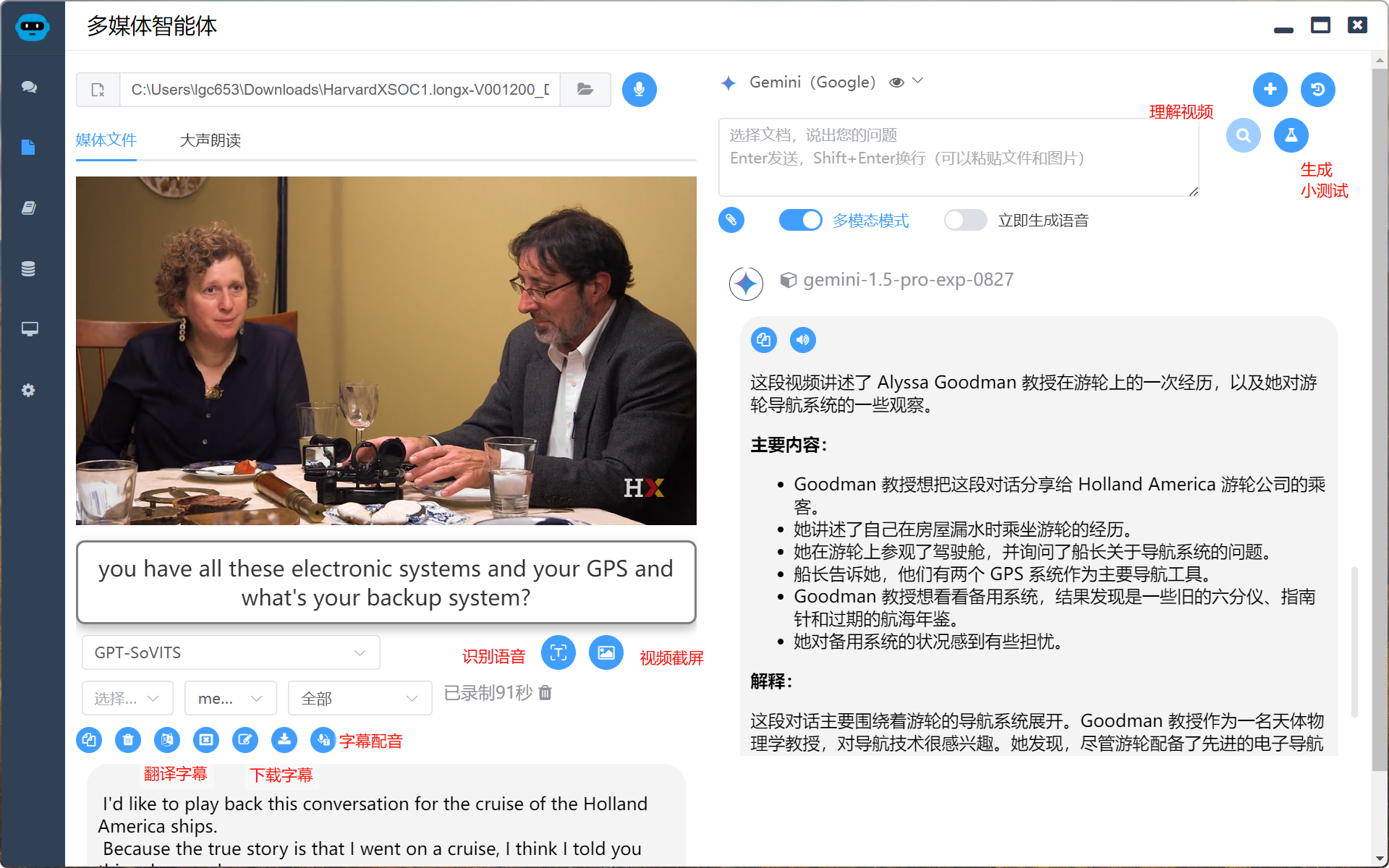
支持全球主流语言
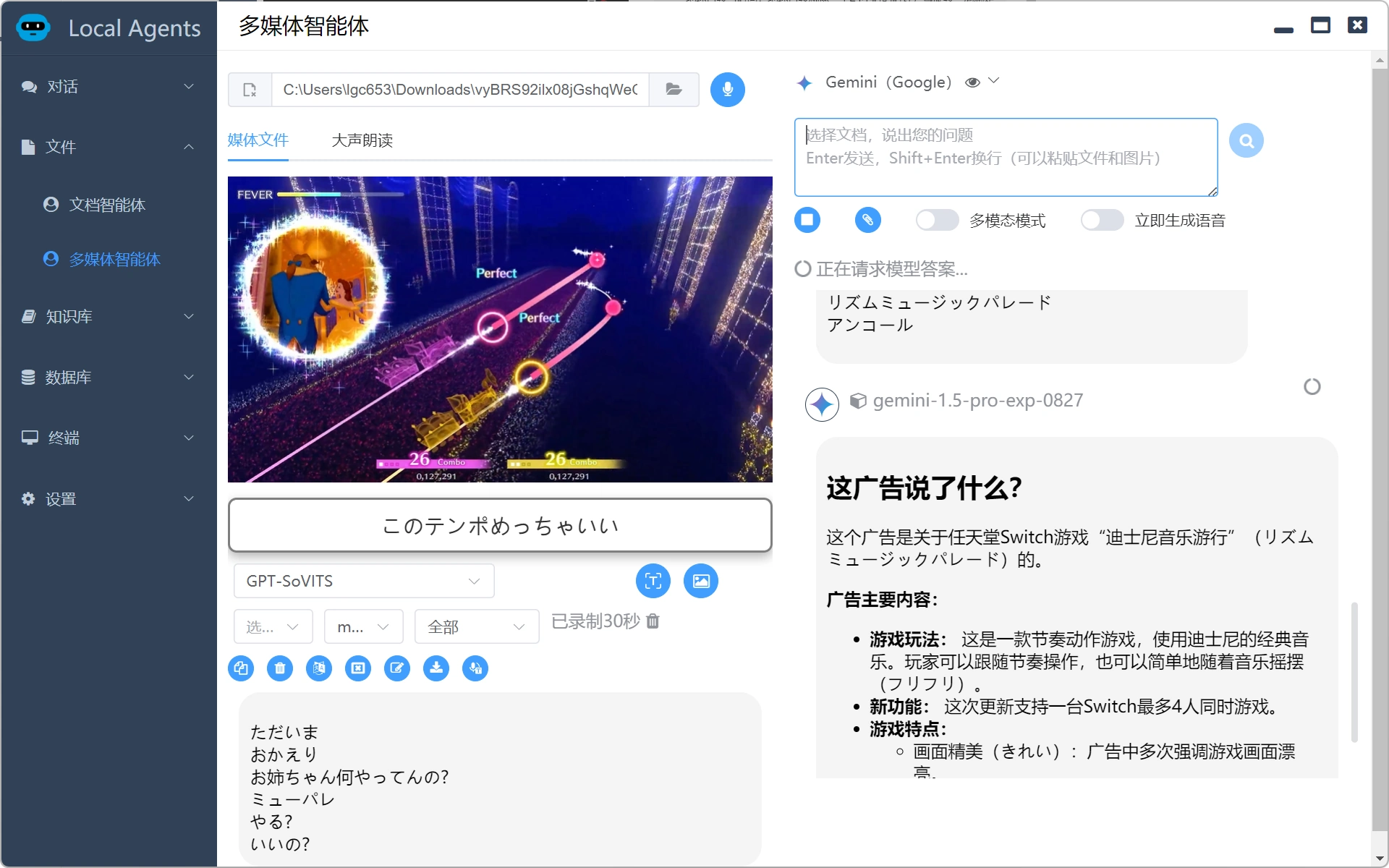
支持听录,不会下载视频,手机上的视频都没问题
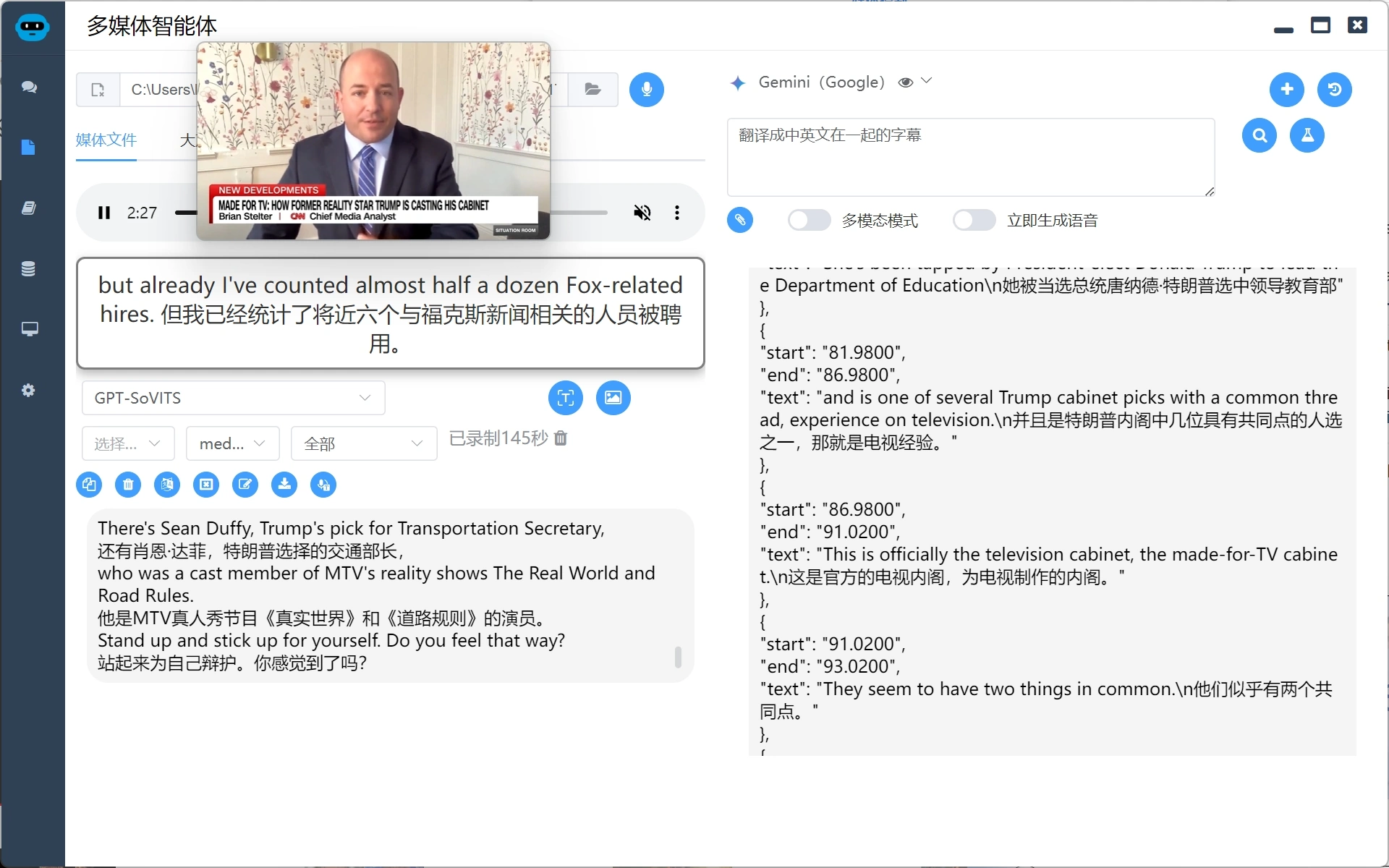
语音合成
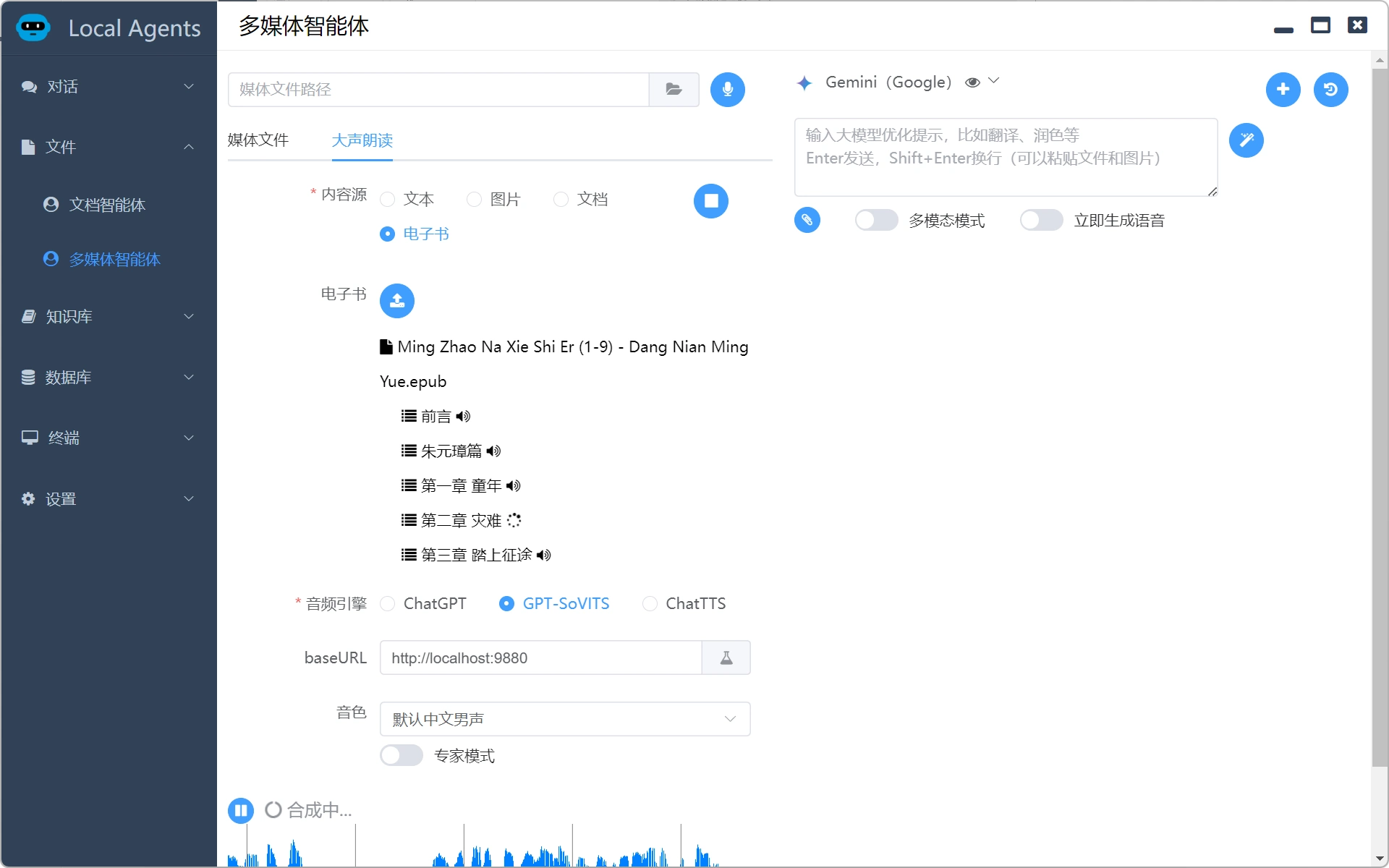
把文本、图片、文档、电子书的内容转为播客
把刚才学习的内容转为播客
太长不想看,长图片一键转换成播客。
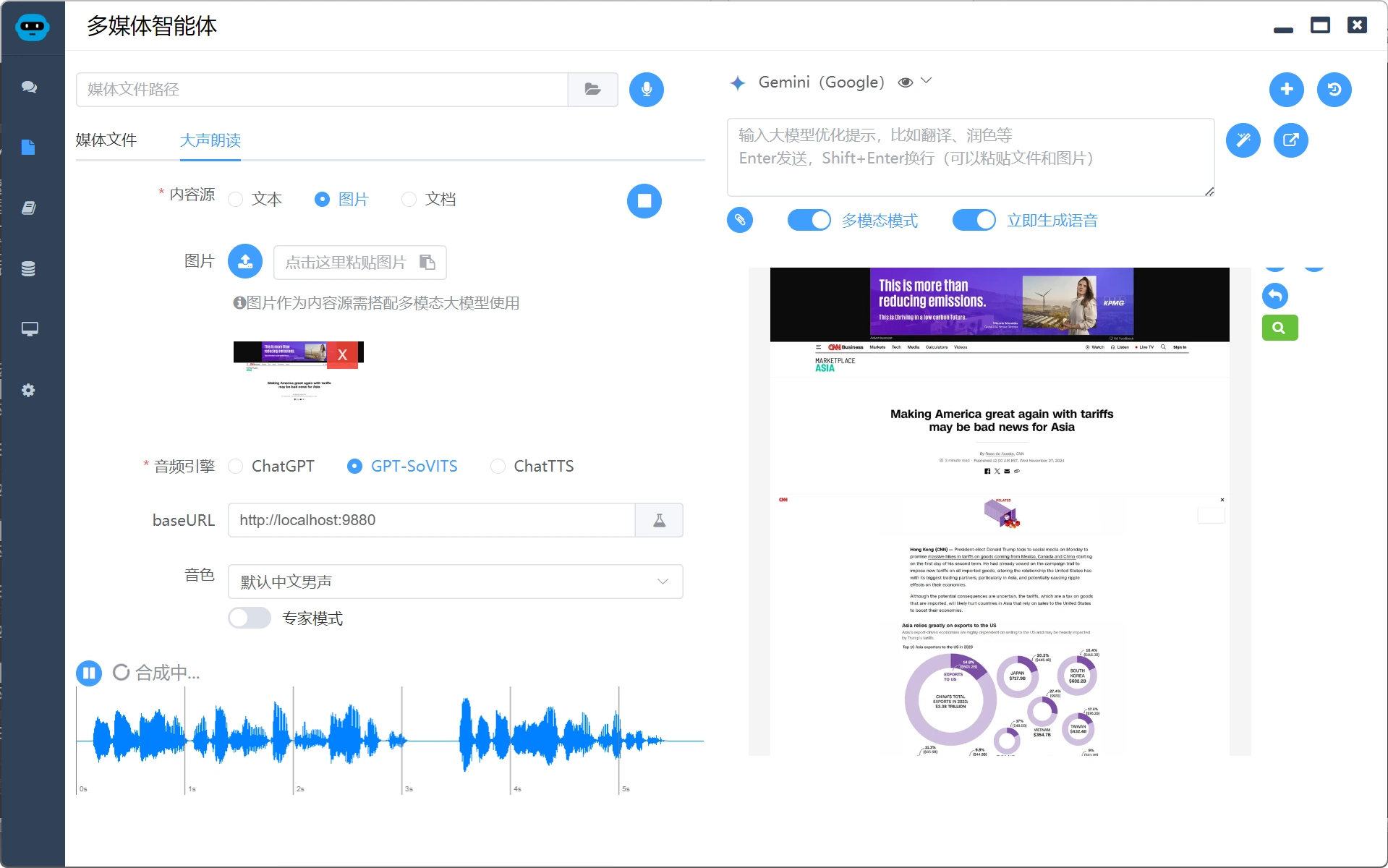
现在微信读书不能听本地书了,这里友情赠送听书功能。
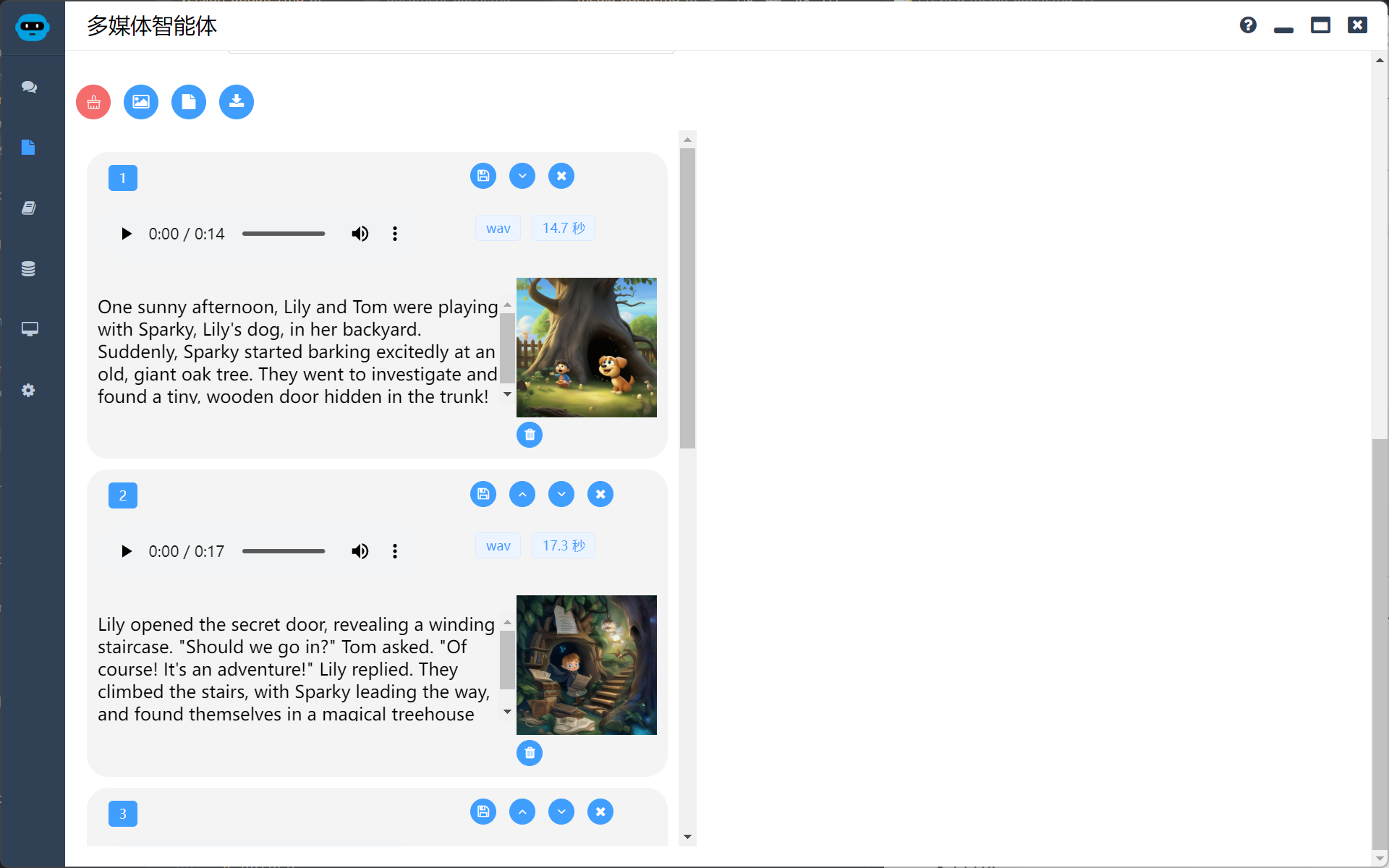
快捷好用的音频制作功能,在大模型协助下根据文稿快速生成配套的音频、视频、字幕。
如下图,用户可以根据文稿快速生成一组音频序列,并给每段音频配图,最终生成视频和字幕。
图片生成
支持如下文生图模型
- dall-e-3
- Stable Diffusion
- Stable Diffusion XL
- FLUX
- Kolors
为刚才生成的播客制作一个封面,直接把生成播客的文字贴给文生图模型
下图使用FLUX生成
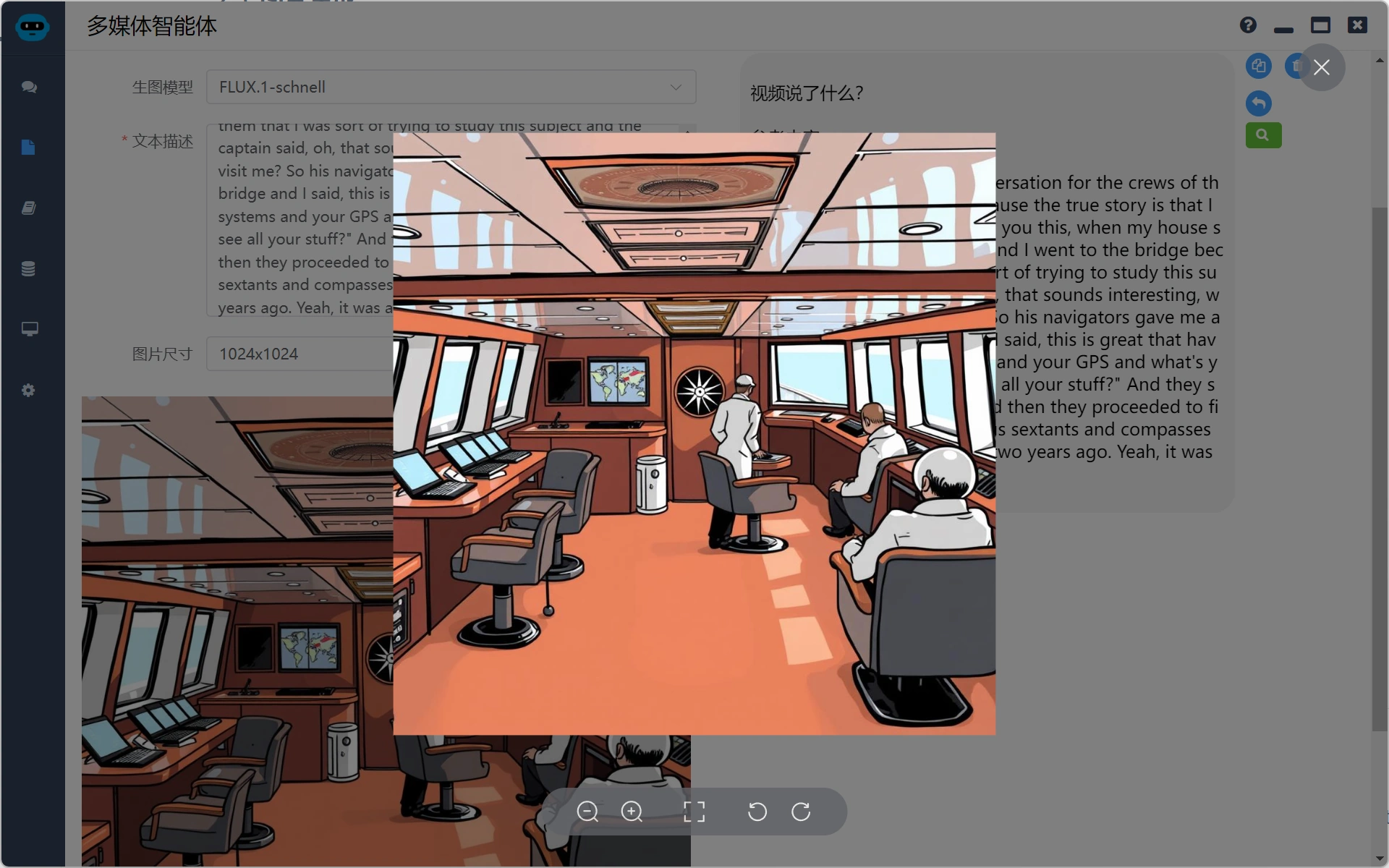
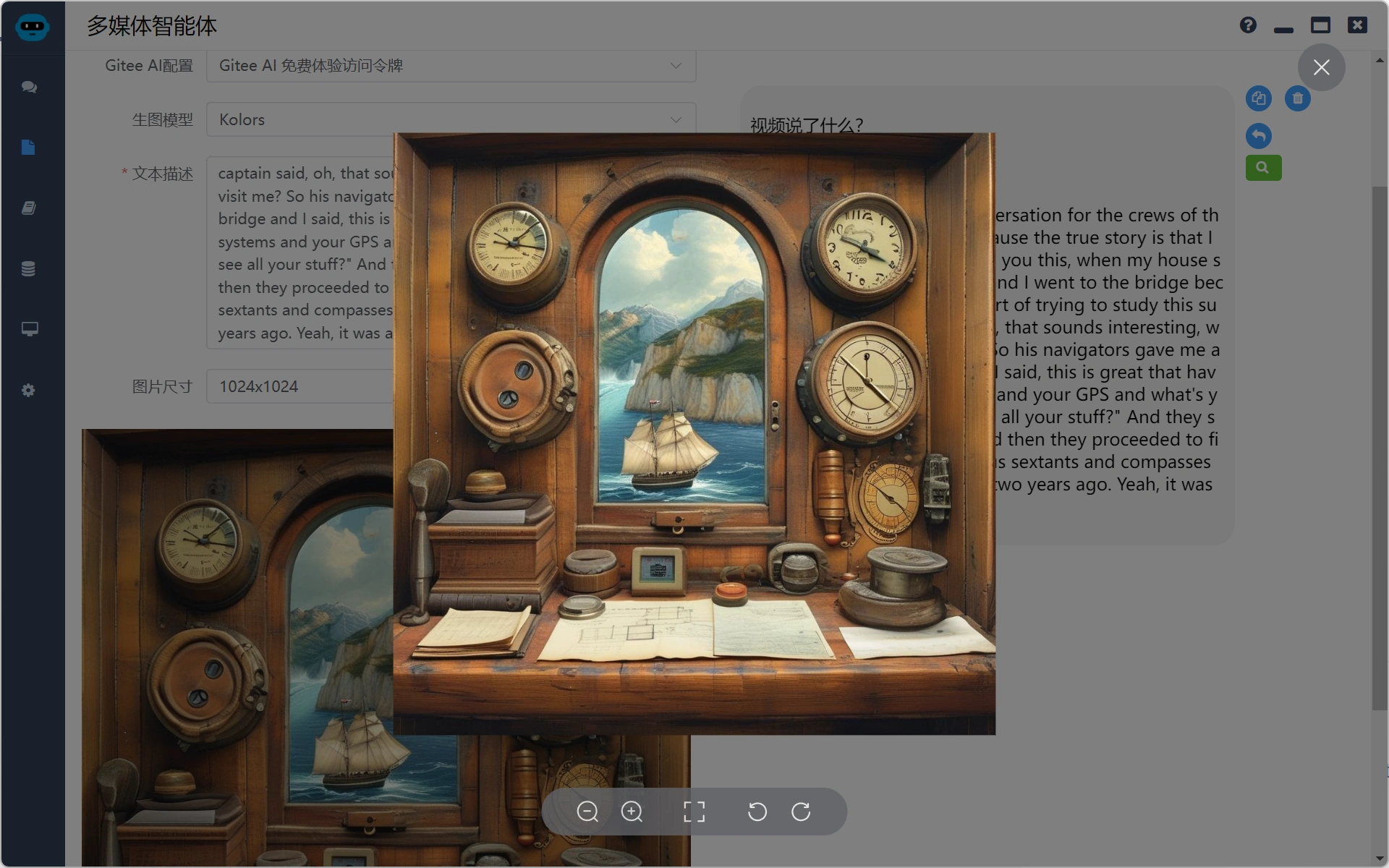
下图使用Kolors生成
语音引擎
语音引擎用于语音识别(ASR技术)和语音合成(TTS技术),这里提供了多种引擎做选择。
语音识别(ASR技术)
- ChatGPT:如果您偶尔用用,或者不差钱(其实也不太贵,1分钟的语音识别费用在4分钱左右),只要在模型中配置了ChatGPT的模型就能用,效果还是不错的。
- GPT-SoVITS:如果您经常使用多媒体功能,推荐您在本地部署GPT-SoVITS,提供丰富的多媒体工具集,不但能语音识别,还能克隆自己的声音,由于GPT-SoVITS提供了整合包,所以配置过程也很方便。
- GPT-SoVITS ASR API:GPT-SoVITS、GPT-SoVITS ASR API引擎实际是利用了GPT-SoVITS整合包中的Faster Whisper工具实现,首次运行时会自动下载模型,请耐心等待。
语音合成(TTS技术)
- ChatGPT:如果您偶尔用用,或者不差钱(其实也不太贵,1千字费用在1毛钱左右),只要在模型中配置了ChatGPT的模型就能用,效果还是不错的,但是感觉有点港台腔。
- GPT-SoVITS:可以去bilibili听听效果。由于GPT-SoVITS提供了整合包,所以配置过程也很方便。
- ChatTTS :可以去chattts.com听听效果。个人觉得不错,爱折腾的人的选择,其实如果你是技术控的话应该很简单。
语音引擎配置
如果您使用GPT-SoVITS整合包方案,只需要2步,如果您想自己研究,这里就不展开了
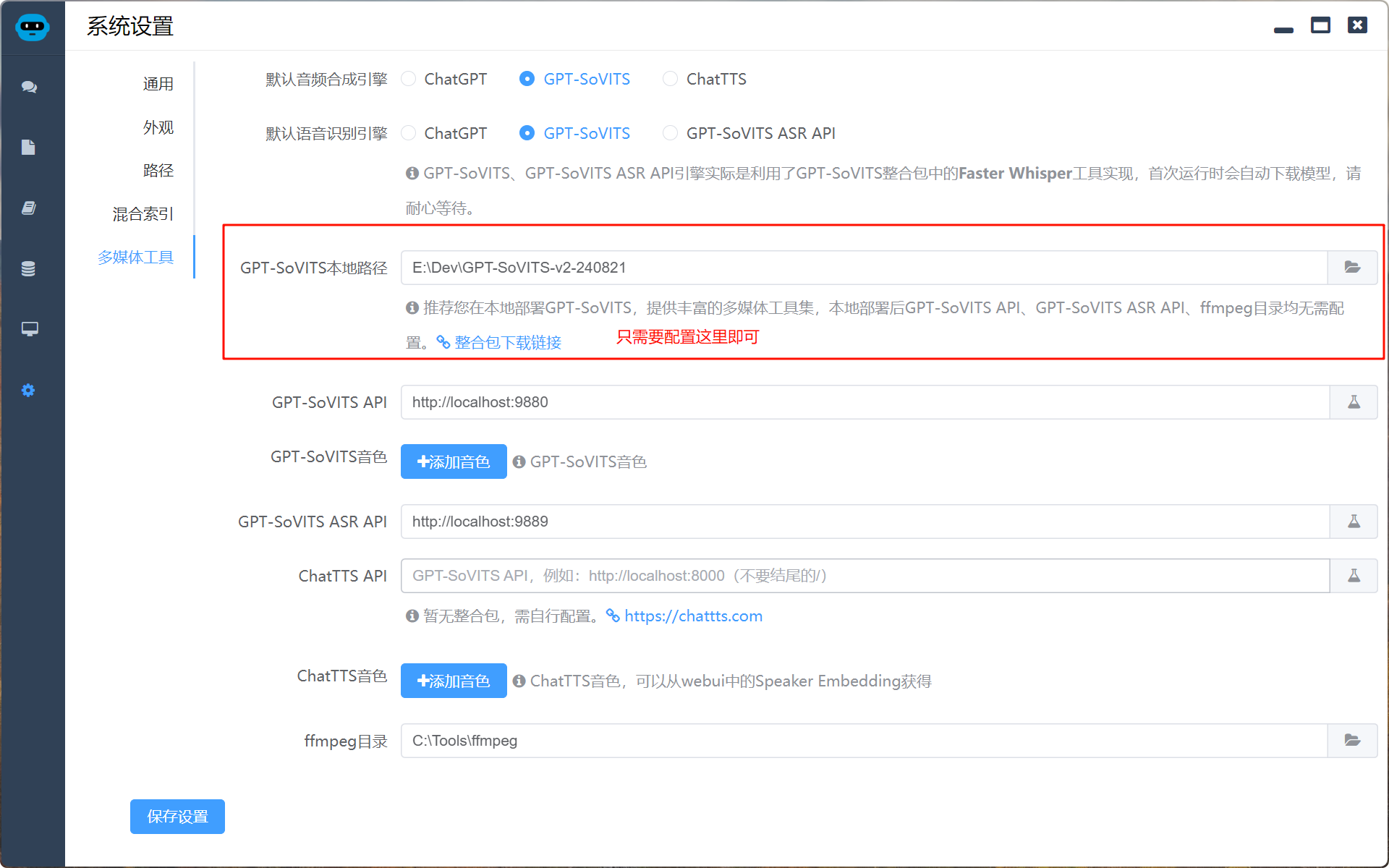
配置GPT-SoVITS本地路径
我使用的是GPT-SoVITS-v2-240821和GPT-SoVITS-v3lora-20250228版本,其它版本未做测试
ffmpeg下载
如果想独立使用ffmpeg,可以去官网下载ffmpeg。当然你也可以在本机搜索一下,说不定你机器上已经有了。
https://ffmpeg.org/download.html
怎么下载视频
- Twitter视频下载网站:twitterfk.com
- 油管视频下载网站:youtube4kdownloader.com